Компания Citrix анонсировала превью очередной версии клиентского гипервизора - XenClient 4.5 Technology Preview. Новая версия клиентского гипервизора, ожидаемая в декабре этого года, будет последователем XenClient 4.1, выпущенной в июле. Напомним, что теперь гипервизор XenClient построен на платформе приобретенного компанией Citrix продукта NxTop.
Новые возможности Citrix XenClient 4.5:
Поддержка новых моделей ультрабуков и 3-го поколения процессоров Intel vPro.
Поддержка ОС Windows 8 в виртуальных машинах.
Поддержка мультиязычности интерфейса клиента: English, French, Spanish, German, Italian, Japanese и Simplified Chinese.
Тэгирование кадров VLAN.
Возможность синхронизации с внешней сетью с использованием NetScaler, что позволяет внешним пользователям иметь доступ к компоненту Synchronizer для их удаленных инсталляций XenClient.
Увеличение скорости загрузки на 30%
Поддержка двух внешних мониторов для док-станций.
Новая технология отображения картинки, позволяющая настраивать размещение и разрешения отдельных мониторов.
Поддержка экспорта виртуальных машин.
Кроме того, был выпущен релиз специализированного клиента Citrix XenClient XT3, который предназначен для организаций с очень высокими требованиями к безопасности и изоляции виртуальных машин. Новые возможности Citrix XenClient XT3:
Компонент Management Synchronizer (Synchronizer XT), который накатывает обновления, удаленно контролирует политики виртуальных машин и работает независимо от остальных компонентов решения.
Возможность изоляции отдельных физических сетевых интерфейсов путем их назначения конкретным ВМ.
Software Development Kit (SDK), позволяющий сторонним компаниям разрабатывать решения в концепции сервисных виртуальных модулей (Linux Service VM appliances).
Поддержка второго и третьего поколений процессоров Intel vPro.
Улучшения механизмов SSL и SELinux.
Соответствие требованиям PL3 и PL4 government.
Те, у кого есть действующая подписка на один из продуктов XenClient, XenDesktop Enterprise или XenDesktop Platinum, могут загрузить XenClient 4.5 Technology Preview по этой ссылке.
Не секрет, что продавать программное обеспечение сейчас - дело неблагодарное и низкомаржинальное, когда дело касается небольших сделок. Когда дело касается большой продажи - это, зачастую, лохотрон, потому как у многих вендоров есть пресловутый механизм "регистрации сделок", который уже давно прогнил и воняет как брошенный у деревенской остановки труп. Почему от него воняет? Очень просто - решение по регистрации сделок целиком лежит на аккаунте вендора, который может быть ангажирован со стороны одного из партнеров, который мотивирует первого разными способами, в том числе Чивасом в помпезном баре или квартальными бонусами. Об этом наши западные друзья, конечно же, знают, но закрывают на это глаза - продавать в Загнивающей как-то же надо.
Они-то знают, как тут строится бизнес и вынуждены работать по правилам, несмотря на то, что заставляют заполнять документы типа "Due Diligence Questionnaire", где сказано куда бежать, если заказчик вымогает взятку. Ну да ладно, речь не об этом.
У тех, кто отвечает за русский прайсинг в VMware - голоса в голове. Когда-то его сделали доступным, потом убрали, теперь он снова на арене, но в новом обличье! Давайте для сравнения заглянем в американский прайс:
И цены наших европейских братьев:
Ого-го, что мы видим. Всего-то мы видим воочию, своими собственными глазами, что:
У нас VMware в 2 раза дороже, чем в Америке.
И чуть поменьше, чем в 2 раза - по отношению к Европе. Это вам даже не Apple со своими Айпадами. Вы вот тут возмущались разнице в цене 30%? Теперь встаньте в стойло и кушайте разницу почти в 100%!
С чем же такое связано? Очень просто - прайс, который вы видите на русском сайте VMware - не совсем настоящий. Какой-то креативный человек в VMware решил провернуть инновационную штуку. А именно: повысить рекомендованные цены для пользователей в России, а для партнеров оставить их прежними (они хоть и не американские, но не в 2 раза же выше). Бедненькие партнеры же страдают со своей копеечной маржой. А тут - нате: давайте вместе считать пользователя мудотрясом и зарабатывать.
Скажу вам по секрету, что старая рекомендованная цена для российского пользователя - как и раньше на 30% выше американской. Поэтому мне ничего не остается, как сказать вам, какую цену вам требовать от партнера - прибавить 30% к американскому прайсу. Это будет адекватно. А этим пусть сама VMware пользуется.
P.S. Если вы донесете это до СМИ или напишете в Спортлото - будет хорошо.
Данная статья посвящена аспектам защиты инфраструктуры виртуальных десктопов, построенной на базе программного обеспечения VMware View. На текущий момент у VMware отсутствуют рекомендации по обеспечению защиты инфраструктуры VMware View наподобие Hardening Guide для VMware vSphere. Точнее сказать они есть, но разрозненны и находятся в различных документах. В части 1 статьи попытаемся рассмотреть рекомендации, которые могут предъявляться к сетевой архитектуре инфраструктуры виртуальных ПК.
Недавно компания Cisco анонсировала скорую доступность бета-версии своего виртуального распределенного коммутатора Cisco Nexus 1000V 2.1, который не только получит много новых возможностей, но и будет иметь бесплатное издание - Essential Edition.
Напомним, что на данный момент актуальная версия коммутатора Cisco Nexus 1000V 1.5.2 работает на VMware vSphere 5.1 и с vCloud Director 5.1 и уже имеет поддержку технологии VXLAN:
В октябре этого года компания Cisco планирует добавить следующие возможности в Cisco Nexus 1000V 2.1:
Поддержка TrustSec SXP позволяет сегментировать виртуальный датацентр на несколько зон безопасности, защищенных политиками, по тэгам SGT:
Появится полноценный плагин к vCenter:
Технология vTracker позволит отслеживать различные процессы и события в сети виртуальной инфраструктуры (например, миграции vMotion):
Модули VSM можно разносить по двум датацентрам в конфигурации Active-Passive:
Теперь о различиях платного (Advanced Edition) и бесплатного (Essential Edition) изданий Cisco Nexus 1000V 2.1:
Пользователи Cisco Nexus 1000V с активной подпиской получают версию 2.1 бесплатно, а также компонент VSG (Virtual Security Gateway) в подарок, который больше отдельно не продается (т.е. его нельзя прикрутить к бесплатному изданию):
Виртуальный распределенный коммутатор Cisco Nexus 1000V будет доступен не только для VMware vSphere, но и для платформ Microsoft Hyper-V, Linux Kernel-Based Virtual Machine (KVM), а также Citrix XenServer. Напомним, что в VMware vSphere его можно использовать только совместно с изданием vSphere Enterprise Plus.
Достаточно давно, известный многим Duncan Epping писал о стартапе CloudPhysics, для которого он является техническим эдвайзором, и который выпускает продукт в виде виртуального модуля (Observer Virtual Appliance), систематизирующий информацию о количественных параметрах виртуальной среды VMware vSphere в виде карточек. На основе этих карточек можно составить заключение о существующих проблемах своей инфраструктуры виртуализации:
Для работы продукта потребуется установить OVA-модуль в своем окружении VMware vSphere, а дальше для просмотра параметров карточек можно использовать веб-консоль (для кого-то это может быть проблемой, так как данные посылаются на сервер CloudPhysics, однако они утверждают, что данные полностью обезличены).
Сами карточки формируются на базе опросов пользователей и всяческих голосований, которые проводятся, например, на конференциях VMworld. Вот примеры таких карточек:
Затем лучшие карточки, будучи реализованными технически, попадают в основной интерфейс продукта (при этом для появления новых карточек не обязательно обновлять виртуальный модуль в своей инсталляции).
Помимо этого есть всякие технические детали о виртуальной инфраструктуре, корелляции параметров и необычные метрики. В общем, для больших инсталляций в плане траблшутинга - штука интересная, попробуйте, это пока бесплатно.
На проходящей с 1 по 3 октября конференции Oracle OpenWorld 2012, компания Oracle объявила о запуске собственного решения для получения вычислительных мощностей из публичного облака в аренду - Oracle IaaS.
Напомним, что на данный момент на рынке облачных инфраструктур IaaS представлено можество компаний:
Amazon AWS - лидер на рынке облачных вычислений, предоставляющий сервисы IaaS на основе гипервизора Xen.
Microsoft Windows Azure - публичное облако Microsoft на основе собственной ветки гипервизора Hyper-V.
Google Compute Engine - анонсированное недавно публичное облако Google, предназначенное для аренды мощностей под ресурсоемкие вычисления.
Помимо этого есть и куча других IaaS-облаков, построенных на базе различных архитектур и решений. Теперь к этой разношерстной компании решила присоединиться и Oracle, планирующая предоставление виртуальных машин в аренду на базе своих программно-аппаратных платформ Exadata, Exalogic и SuperCluster. Помимо этого, было анонсировано решение для построения частных облаков организаций Oracle Private Cloud. Сама Oracle планирует прямую конкуренцию с Cloud-платформой Amazon AWS.
Интересная особенность Private Cloud - в случае ее развертывания на площадке клиента, Oracle будет управлять и обслуживать ее на базе платы за потребление ресурсов в месяц. То есть, специалисты Oracle будут администрировать ЦОД компании на ее территории.
При этом будет обеспечена совместимость при перемещении виртуальных машин между собственной инфраструктурой и облаком Oracle. Предлагаются также DR-сценарии и решения по заимствованию мощностей в случае отсутствия собственных под решение насущных задач:
Кроме всего этого, Oracle будет продолжать предоставлять сервисы PaaS для разработки и размещения приложений (для своей БД и Java), а также приложения по модели SaaS - CRM, HCM, ERP и другие.
Вот так выглядел Oracle Public Cloud в 2011 году, когда облако IaaS еще не было представлено:
Посмотрим, как это будет выглядеть сейчас - следите за обновлениями cloud.oracle.com. Когда все это будет - неизвестно.
С 3 по 5 октября в Экспоцентре пройдет отраслевая конференция по информационной безопасности INFOBEZ-EXPO 2012, где, конечно же, будут представлены решения российского производителя "Код Безопасности", выпускающего продукт vGate R2 для защиты инфраструктур виртуализации VMware vSphere средствами политик и механизма защиты от НСД.
Компания «Код Безопасности» представит на выставке новые версии своих продуктов, предназначенных для защиты государственной и коммерческой тайны, персональных данных. Также на выставке будет презентован первый на российском рынке защищенный планшетный компьютер «Континент Т-10», предназначенный для организации безопасного доступа мобильных сотрудников к защищенным ресурсам корпоративной сети.
Ежедневно на стенде компании «Код Безопасности» в оборудованной презентационной зоне ведущие эксперты компании будут проводить презентации новых продуктов и отвечать на вопросы посетителей выставки об особенностях их применения. Авторы самых интересных вопросов на каждой презентации получат сувениры с фирменной символикой компании «Код Безопасности».
Расписание презентаций:
3 октября 2012 г
11:30-12:00 Новые возможности Secret Net 7
14:00-14:30 Защита информации в виртуальных средах при помощи vGate R2
16:00-16:30 Новые возможности TrustAccess 1.3
4 октября 2012
12:00-12:30 Новые возможности TrustAccess 1.3
14:00-14:30 Новые возможности Secret Net 7
15:30-16:00 Защита информации в виртуальных средах при помощи vGate R2
5 октября 2012
11:00-11:30 Защита информации в виртуальных средах при помощи vGate R2
13:00-13:30 Новые возможности Secret Net 7
Приглашаем вас посетить стенд компании «Код Безопасности» № 1-200 и принять участие в мероприятиях, организованных компанией для посетителей выставки INFOBEZ-EXPO 2012. Участие в конференции - бесплатное.
Мы уже много писали о сравнении платформ виртуализации VMware vSphere с Microsoft Hyper-V в ОС Windows Server. Когда гипервизор Hyper-V был еще второй версии - безусловно, все такиесравнениявыигрывала VMware, кроме воттаких - весьма глупых по своей сути.
В итоге, поняв, что надо как-то отбиваться от маркетинговых вбросов Microsoft, весной компания VMware обратилась к известным каталам сферы виртуализации - компании Principled Technologies, которая сваяла в начале года очередной отчет "Total Cost Comparison: VMware vSphere vs. Microsoft Hyper-V", где vSphere 5 сравнивалась с Hyper-V в ключе затрат на администрирование инфраструктуры:
Этот отчет интересен, прежде всего тем, что в нем много внимание уделено различным типам операций в виртуальной инфраструктуре, которые требовали много времени в Hyper-V R2, наример, Quick Storage Migration:
Теперь такого с Hyper-V не провернешь - там есть и горячая миграция хранилищ, и прочие интересные вещи. Однако сам отчет почитать стоит, чтобы понять тот малый объем юзкейсов для СМБ, в котором инфраструктура VMware сэкономит деньги по сравнению с Microsoft.
Теперь обратим взор к свежей презентации "The VMware Advantage Over Hyper-V 3", сделанной 4 сентября этого года.
Посмотрим, что нам там пытается впарить VMware в ответ на это. Много поддерживаемых ОС - это хорошо:
А вот, что касается функционала (кликабельно):
По-сути, Hyper-V 3 обвиняется в двух основных грехах - слабая подсистема безопасности и отсутствие некоторых Enterprise-возможностей для работы с виртуальными машинами и хранилищами, такими как Storage DRS, SIOC, Auto Deploy и Host Profiles - все эти вещи есть только в издании Enterprise Plus, которое в разы дороже соответсвующего количества лицензий SC VMM и других необходимых компонентов System Center для построения виртуальной инфраструктуры на Hyper-V. Кроме того, нужность всех этих вещей для СМБ - под большим вопросом.
Опять идет неубедительный FUD про долгие операции в Hyper-V и быстрые в vSphere:
Ну и традиционное полотно про превосходство добра над злом:
Большинство из того, что здесь написано - это либо субъективное мнение VMware, либо Enterprise-возможности из дорогущего издания Enterprise Plus. Поэтому, это еще один способ убедиться, что VMware работает на Enterprise, не уделяя рынку СМБ должного внимания, в котором Microsoft в ближайшее время может перетянуть очень большое количество клиентов.
Мы уже писали о том, что такое и как работает технология VMware vStorage API for Array Integration (VAAI) (а также немного тут), которая позволяет передать операции по работе с хранилищами, которые выполняет компонент Data Mover в VMkernel, на сторону дискового массива. Это существенно улучшает показатели производительности различных операций (клонирования и развертывания ВМ, использования блокировок) за счет того, что они выполняются самим массивом, без задействования сервера VMware ESXi:
Если ваш массив не поддерживает примитивы VAAI, то чтобы склонировать виртуальный диск VMDK размером 64 ГБ, компонент Data Mover реализует эту операцию следующим образом:
Разделяет диск 64 ГБ на малые порции размером в 32 МБ.
Эту порцию 32 МБ Data Mover разделяет еще на маленькие операции ввода-вывода (I/O) размером в 64 КБ, которые идут в 32 параллельных потока одновремнно.
Соответственно, чтобы передать 32 МБ, Data Mover выполняет 512 операций ввода вывода (I/Os) по 64 КБ.
Если же массив поддерживает примитив XCOPY (он же Hardware Offloaded Copy и SAN Data Copy Offloading), то для передачи тех же 32 МБ будут использованы I/O размером в 4 МБ, а таких I/O будет, соответственно, всего 8 штук - разница очевидна.
Интересно, как работает VAAI с точки зрения ошибок при передаче данных: например, мы делаем клонирование ВМ на массиве с поддержкой VAAI, и вдруг возникает какая-то ошибка. В этом случае VMkernel Data Mover подхватывает операцию клонирования с того места, где VAAI вызвал ошибку, и производит "доклонирование" виртуальной машины. Далее ESXi периодически будет пробовать снова использовать VAAI на случай, если это была кратковременная ошибка массива.
При этом проверки в разных версиях ESXi будут производиться по-разному:
Для ESX/ESXi 4.1 проверка будет производиться каждые 512 ГБ передаваемых данных. Посмотреть этот параметр можно следующей командой:
# esxcfg-advcfg -g /DataMover/HardwareAcceleratedMoveFrequency Value of HardwareAcceleratedMoveFrequency is 16384
Это значение частоты 16384 нужно умножить на порцию 32 МБ и мы получим 512 ГБ. Чтобы поменять эту частоту, можно использовать команду:
Для ESXi 5.0 и выше все проще - проверка производится каждые 5 минут.
Помимо описанных в нашей статье примитивов Full Copy, Zero Block и ATS, начиная с версии ESXi 5.0, поддерживаются еще 2 примитива:
Thin Provisioning - механизм сообщения хостом ESXi дисковому массиву о том, что виртуальная машина или ее файлы с Thin LUN были удалены или перемещены (в силу разных причин - Storage vMotion, консолидация снапшотов и так далее), поэтому массив может забрать это дисковое пространство себе назад.
С точки зрения дисковых массивов, работающих на NFS (прежде всего, NetApp) в ESXi 5.0 также появилась поддержка примитивов VAAI:
Full File Clone – аналог функций Full Copy для VAAI на блочных хранилищах, предназначен для клонирования файлов виртуальных дисков VMDK.
Native Snapshot Support – передача на сторону массива функций создания снапшота ВМ.
Extended Statistics – включает возможность просмотра информации об использовании дискового пространства на NAS-хранилище, что полезно для Thin Provisioning.
Reserve Space – включает возможность создания виртуальных дисков типа "thick" (фиксированного размера) на NAS-хранилищах (ранее поддерживались только Thin-диски).
Функции VAAI включены по умолчанию и будут использованы тогда, когда станут доступны (например, при обновлении Firmware дискового массива, которое поддерживает VAAI).
Таги: VMware, vSphere, VAAI, Storage, ESXi, Enterprise, SAN
Если речь идет о виртуальных машинах на сервере VMware ESXi, работающих с дисковым массивом, можно выделить 5 видов очередей:
GQLEN (Guest Queue) - этот вид очередей включает в себя различные очереди, существующие на уровне гостевой ОС. К нему можно отнести очереди конкретного приложения, очереди драйверов дисковых устройств в гостевой ОС и т.п.
WQLEN (World Queue/ Per VM Queue) - это очередь, существующая для экземпляра виртуальной машины (с соответствующим World ID), которая ограничивает единовременное число операций ввода-вывода (IOs), передаваемое ей.
AQLEN (Adapter Queue) - очередь, ограничивающая одновременное количество обрабатываемых на одном HBA-адаптере хоста ESXi команд ввода вывода.
DQLEN (Device Queue / Per LUN Queue) - это очередь, ограничивающая максимальное количество операций ввода-вывода от хоста ESXi к одному LUN (Datastore).
Эти очереди можно выстроить в иерархию, которая отражает, на каком уровне они вступают в действие:
Очереди GQLEN бывают разные и не относятся к стеку виртуализации VMware ESXi, поэтому мы рассматривать их не будем. Очереди SQLEN мы уже частично касались тут и тут. Если до SP дискового массива со стороны сервера ESX / ESXi используется один активный путь, то глубина очереди целевого порта массива (SQLEN) должна удовлетворять следующему соотношению:
SQLEN>= Q*L
где Q - это глубина очереди на HBA-адаптере, а L - число LUN, обслуживаемых SP системы хранения. Если у нас несколько активных путей к одному SP правую часть неравенства надо еще домножить на P - число путей.
Соответственно, в виртуальной инфраструктуре VMware vSphere у нас несколько хостов имеют доступ к одному LUN через его SP и получается следующее соотношение:
SQLEN>= ESX1 (Q*L*P) + ESX2 (Q*L*P)+ и т.д.
Теперь рассмотрим 3 оставшиеся типа очередей, которые имеют непосредственное отношение к хосту VMware ESXi:
Как мы видим из картинки - очереди на различных уровнях ограничивают число I/O, которые могут быть одновременно обработаны на различных сущностях:
Длина очереди WQLEN по умолчанию ограничена значением 32, что не позволяет виртуальной машине выполнять более 32-х I/O одновременно.
Длина очереди AQLEN - ограничена значением 1024, чтобы собирать в себя I/O от всех виртуальных машин хоста.
Длина очереди DQLEN - ограничена значением 30 или 32, что не позволяет "выедать" одному хосту ESXi с одного хранилища (LUN) более 30-ти или 32-х операций ввода-вывода
Зачем вообще нужны очереди? Очень просто - очередь это естественный способ ограничить использование общего ресурса. То есть одна виртуальная машина не заполонит своими командами ввода-вывода весь HBA-адаптер, а один хост ESXi не съест всю производительность у одного Datastore (LUN), так как ограничен всего 32-мя I/O к нему.
Мы уже писали о функционале Storage I/O Control (SIOC), который позволяет регулировать последний тип очереди, а именно DQLEN, что позволяет корректно распределить нагрузку на СХД между сервисами в виртуальных машинах в соответствии с их параметрами shares (эта функциональность есть только в издании vSphere Enterprise Plus). Механизм Storage IO Control для хостов VMware ESX включается при превышении порога latency для тома VMFS, определяемого пользователем. Однако, стоит помнить, что механизм SIOC действует лишь в пределах максимально определенного значения очереди, то есть по умолчанию не может выйти за пределы 32 IO на LUN от одного хоста.
Для большинства случаев этого достаточно, однако иногда требуется изменить обозначенные выше длины очередей, чтобы удовлетворить требования задач в ВМ, которые генерируют большую нагрузку на подсистему ввода-вывода. Делается это следующими способами:
1. Настройка длины очереди WQLEN.
Значение по умолчанию - 32. Его задание описано в статье KB 1268. В Advanced Settings хоста ESXi нужно определить следующий параметр:
Disk.SchedNumReqOutstanding (DSNRO)
Он глобально определяет, сколько операций ввода-вывода (IOs) может максимально выдать одна виртуальная машина на LUN одновременно. В то же время, он задает это максимальное значение в IOs для всех виртуальных машин на этот LUN от хоста ESXi (это глобальная для него настройка). То есть, если задано значение 32, то все машины могут одновременно выжать 32 IOs, это подтверждается в случае, где 3 машины генерируют по 32 одновременных IO к одному LUN, а реально к LUN идут все те же 32, а не 3*32.
2. Настройка длины очереди AQLEN.
Как правило, этот параметр менять не требуется, потому что дефолтного значения 1024 хватает практически для всех ситуаций. Где его менять, я не знаю, поэтому если знаете вы - можете написать об этом в комментариях.
3. Настройка длины очереди DQLEN.
Настройка этого параметра описана в KB 1267 (мы тоже про это писали) - она зависит от модели и драйвера HBA-адаптера (в KB информация актуальна на июнь 2010 года). Она взаимосвязана с настройкой Disk.SchedNumReqOutstanding и, согласно рекомендациям VMware, должна быть эквивалентна ей. Если эти значения различаются, то когда несколько ВМ используют с хоста ESXi один LUN - актуальной длиной очереди считается минимальное из этих значений.
Для отслеживания текущих значений очередей можно использовать утилиту esxtop, как описано в KB 1027901.
Для тех, кто активно использует инфраструктуру виртуальных ПК на базе решения VMware View, на сайте проекта VMware Labs появился интересный скрипт - View Controlled Recompose Script. Как знают пользователи VMware View, при необходимости обновления десктопов можно сделать операцию "Recompose", где, выбрав обновленный снапшот базовой ВМ или другую базовую ВМ, можно перестроить виртуальные машины пользователей пула ПК на работу с новым диском, не затрагивая диск с пользовательскими данными:
В отличие от стандартых средств по рекомпозиции в VMware View Manager, в скрипте View Controlled Recompose производится интеллектуальная процедура: через интерфейс WMI производится определение неиспользуемых виртуальных машин, после чего один из таких десктопов используется как реплика (Replica VM), а далее для неиспользуемых десктопов происходит рекомпозиция на базе этой реплики. Потом для активных десктопов можно сделать Force Logoff и перенаправить пользователей на уже рекомпозированные виртуальные ПК, а для этих активных десктопов, в свою очередь, доделать рекомпозицию.
По умолчанию скрипт работает в интерактивном режиме и принимает следующие входные параметры:
Pool - пул виртуальных ПК для рекомпозиции
ParentVM - полный путь к базовому образу
NewSnapshot - полный путь к снапшоту образа, из которого будет создаваться реплика и делаться рекомпозиция
Скрипт необходимо запускать на сервере VMware View Connection Server, сам же скрипт сделан на PowerCLI / PowerShell. Более подробные инструкции по его использованию приведены по этой ссылке.
Скачать скрипт VMware View Controlled Recompose Script можно по этой ссылке.
Виктор прислал мне презентацию от того самого Ивана, который на одной из юзер-групп VMware рассматривал особенности дизайна и проектирования виртуальной инфраструктуры VMware vSphere. Часть, касающаяся виртуализации различных типов нагрузок в гостевых ОС виртуальных машин показалась мне очень интересной, поэтому я решил перевести ее и дополнить своими комментариями и ссылками. Итак, что следует учитывать при переносе и развертывании различных приложений в виртуальных машинах на платформе vSphere.
Таги: VMware, vSphere, ESXi, HA, Enterprise, VMachines
Но нас с вами интересует, конечно же, не это. Главная для нас новость - это анонс нового публичного IaaS-облака от интернет-гиганта, которое называется Google Compute Engine. На конференции было продемонстрировано приложение по обсчету генома, запущенное в кластере из 1250 виртуальных машин (у каждой 8 ядер) на этой платформе, что, возможно, намекает на направленность Google на сегмент "Big Data", а также научные и исследовательские задачи крупных компаний и университетов.
Google Compute Engine - это новый сервис аренды вычислительных сред в публичном облаке (IaaS) на базе ОС Linux, предоставляющий услуги на базе платы за почасовое потребление ресурсов (вычислительные мощности и хранилища). Поддержки Windows в данных вычислительных средах пока не заявлено. Напомним, что у Google уже есть PaaS-платформа App Engine и сервис облачного хранения Cloud Storage. Сам сервис Compute Engine (CE) доступен для пробного использования только по приглашениям (Limited Preview).
Таким образом, мы получаем трех потенциальных лидеров рынка IaaS-сервисов из публичного облака: старейший Amazon AWS, анонсированный в начале июня Microsoft Windows Azure и Google Compute Engine. Особняком стоит компания VMware, предоставляющая решения VMware vCloud, на базе которых любой сервис-провайдер может построить публичное облако. При этом VMware не скрывает своей направленности исключительно на крупный корпоративный сектор (сейчас существует около 125 сертифицированных публичных облаков vCloud от партеров VMware по программе VSPP в 26 странах, которые предлагают аренду виртуальных машин). Отметим также и решение Citrix Xen Cloud Platform от компании Citrix и сообщества Xen.
Основные особенности Google Compute Engine:
Вычислительные среды. Доступны в конфигурации 1,2,4 или 8 ядер на Linux-платформе с 3,75 ГБ оперативной памяти на одно ядро.
Хранилища. Можно хранить данные виртуальных машин в виде непостоянных (Ephemeral), а также постоянных (Persistent) дисков на стороне Google или в сервисе Google Cloud Storage. Для постоянных дисков можно делать снапшоты в целях резервного копирования, а также предоставлять доступ к одному диску со стороны нескольких ВМ. Все данные дисков шифруются.
Сетевое взаимодействие. Возможность использовать высокопроизводительное сетевое оборудование датацетров Google и самостоятельно конфигурировать сетевые экраны, также использовать внешний IP-адрес. Плюс готовые решения от сторонних вендоров, которые выступают партнерами Google.
Управление. Виртуальными машинами можно будет управлять через веб-консоль или CLI, также есть API, предоставляющий множество возможностей разработчикам и сторонним производителям.
Google Compute Engine будет интегрирован с партнерскими решениями RightScale, Puppet Labs,OpsCode, Numerate, Cliqr, MapR и другими.
Безусловно, Google вступает на рынок IaaS-решений довольно поздно. Но это только одна сторона медали - на самом деле, более 90% компаний вообще еще не пользовались облачными ресурсами уровня IaaS, поэтому потенциал рынка огромный. Также отметим возможную "нишевость" сервиса от Google, если он будет направлен на высокопроизводительные вычисления по цене существенно меньшей, чем у конкурентов.
Значение GCEU (Google Compute Engine Units), которое вы видите в правой колонке - это аналог Amazon EC2 Compute Unit (как написано тут), т.е. где-то эквивалент 1.0-1.2 ГГц на процессорах 2007 Opteron or 2007 Xeon.
Также на сайте thenextweb.com проведено сравнение анонсированных цен на Google Compute Engine и уже объявленных Microsoft на Windows Azure. По расчетам получается, что при где-то одинаковой цене мощностей Google Compute Engine и Windows Azure, сервис от Google дает на 50% больше оперативной памяти для ВМ.
Мы уже недавно писали о метриках производительности хранилищ в среде VMware vSphere, которые можно получить с помощью команды esxtop. Сегодня мы продолжим развивать эту тему и поговорим об общей производительности дисковых устройств и сайзинге нагрузок виртуальных машин по хранилищам в виртуальной среде.
Как говорит нам вторая статья блога VMware о хранилищах, есть несколько причин, по которым может падать производительность подсистемы ввода-вывода виртуальных машин:
Неправильный сайзинг хранилищ для задач ВМ, вследствие чего хранилища не выдерживают такого количества операций, и все начинает тормозить. Это самый частый случай.
Перегрузка очереди ввода-вывода со стороны хост-сервера.
Достижение предела полосы пропускания между хостом и хранилищем.
Высокая загрузка CPU хост-сервера.
Проблемы с драйверами хранилищ на уровне гостевой ОС.
Некорректно настроенные приложения.
Из всего этого набора причин самой актуальной оказывается, как правило, первая. Это происходит вследствие того, что администраторы очень часто делают сайзинг хранилищ для задач в ВМ, учитывая их требования только к занимаемому пространству, но не учитывая реальных требований систем к вводу выводу. Это верно в Enterprise-среде, когда у вас есть хранилища вроде HDS VSP с практически "несъедаемой" производительностью, но неверно для Low и Midrange массивов в небольших организациях.
Поэтому профилирование нагрузки по хранилищам - одна из основных задач администраторов VMware vSphere. Здесь VMware предлагает описывать модель нагрузки прикладной системы следующими параметрами:
Размер запроса ввода-вывода (I/O Size)
Процент обращений на чтение (Read)
Процент случайных обращений (Random)
Таким образом профиль приложения для "типичной" нагрузки может выглядеть наподобие:
8KB I/O size, 80% Random, 80% Read
Само собой, для каждого приложения типа Exchange или СУБД может быть свой профиль нагрузки, отличающийся от типичного. Размер запроса ввода-вывода (I/O Size) также зависит от специфики приложения, и о том, как регулировать его максимальное значение на уровне гипервизора ESXi, рассказано в KB 1008205. Нужно просто в Advanced Settings выставить значение Disk.DiskMaxIOSize (значение в килобайтах). Некоторые массивы испытывают проблемы с производительностью, когда размер запроса ввода-вывода очень велик, поэтому здесь нужно обратиться к документации производителя массива. Если с помощью указанной настройки ограничить размер запроса ввода-вывода, то они будут разбиваться на маленькие подзапросы, что может привести к увеличению производительности подсистемы ввода-вывода на некоторых системах хранения. По умолчанию установлено максимальное значение в 32 МБ, что является достаточно большим (некоторые массивы начинают испытывать проблемы при запросах более 128 KB, 256 KB или 512KB, в зависимости от модели и конфигурации).
Однако вернемся к профилированию нагрузок по хранилищам в VMware vSphere. В одной из презентаций VMware есть замечательная картинка, отражающая численные характеристики производительности дисковых устройств в пересчете на шпиндель в зависимости от типа их организации в RAID-массивы:
Параметры в верхней части приведены для операций 100%-й последовательной записи для дисков на 15К оборотов. А в нижней части приведены параметры производительности для описанной выше "типичной" нагрузки, включая среднюю скорость чтения-записи, число операций ввода-вывода в секунду (IOPS) и среднюю задержку. Хорошая напоминалка, между прочим.
Теперь как анализировать нагрузку по вводу выводу. Для этого у VMware на сайте проекта VMware Labs есть специальная утилита I/O Analyzer, про которую мы уже писали вот тут. Она может многое из того, что потребуется для профилирования нагрузок по хранилищам.
Ну а дальше стандартные процедуры - балансировка нагрузки по путям, сторадж-процессорам (SP) и дисковым устройствам. Сигналом к изысканиям должен послужить счетчик Device Latency (DAVG) в esxtop, если его значение превышает 20-30 мс для виртуальной машины.
Мы уже давно писали о новых возможностях продукта номер 1 для защиты виртуальных инфраструктур - vGate R2 с поддержкой VMware vSphere 5, а также о получении им всех необходимых сертификатов ФСТЭК. Теперь же новые версии продуктов vGate R2 и vGate S R2 официально поступили в продажу и доступны для заказа у партнеров компании Код Безопасности.
Среди основных возможностей новой версии продукта:
Полная поддержка VMware vSphere 5
Новый интерфейс просмотра отчетов. Для построения отчетов больше не требуется наличие SQL-сервера, устанавливаемого ранее отдельно.
Поддержка новых стандартов и лучших практик в политиках и шаблонах (VMware Security Hardening 4.1, PCI DSS 2.0, CIS VMware ESX Server Benchmark 4).
Поддержка распределенного коммутатора (Distributed vSwitch) Cisco Nexus 1000v.
Поддержка 64-битных систем в качестве платформы для vGate Server.
Улучшение юзабилити, пользовательного интерфейса и масштабируемости.
Из официального пресс-релиза компании Код Безопасности:
Компания «Код Безопасности» сообщает о передаче в продажу новых версий сертифицированного программного продуктаvGate R2/ vGate S R2, предназначенного для защиты от НСД систем управления виртуализированных инфраструктур, построенных на платформах VMware. Новые версии продуктов доступны для приобретения с начала мая 2012 года.
Новые сертифицированные версии vGate R2/ vGate S R2 содержат ряд значительных улучшений и функциональных модернизаций, которые позволяют наиболее полно решать задачи компаний по обеспечению безопасности информации, обрабатываемой и хранящейся в инфраструктурах, построенных на платформах VMware.
В частности, добавлена возможность поддержки инфраструктур виртуализации, распределенных по нескольким подсетям. Также в новых сертифицированных версиях для удобства работы администраторов улучшены возможности фильтрации списков защищаемых объектов: теперь фильтрация может производиться по объектам (ВМ, сервер и др.).
Улучшены возможности работы с отчетами аудита – теперь возможна фильтрация по описанию событий.
Значительно улучшен конфигуратор продукта, который в новых версиях запускается сразу после установки и позволяет сделать необходимые настройки продукта таким образом, чтобы можно было начать его использование непосредственно после установки.
Относительно поддержки аппаратных средств в новых версиях vGate R2/ vGate S R2 теперь предусмотрена поддержка работы с Distributed vSwitch Cisco Nexus 1000v. Улучшения коснулись и шаблонов автоматического приведения систем в соответствие с требованиями лучших практик и стандартов. Теперь с помощью vGate R2/ vGate S R2 можно автоматизировать привидение систем в соответствие с требованиями следующих лучших документов:
vSphere 4.1 Security Hardening Guide,
CIS Security Configuration Benchmark for VMWare ESX 4 v. 1.0,
PCI DSS версия 2.0.
По-прежнему компаниям-пользователям остаются доступны шаблоны автоматического приведения систем в соответствие с ФЗ-152 и СТО БР ИББС.
Пробную версию продукта vGate R2 можно скачать бесплатно по этой ссылке.
Одновременно с выпуском новой версии решения для виртуализации настольных ПК предприятия VMware View 5.1 компания VMware выпустила также средство централизованного мониторинга и поддержки жизнеспособности инфраструктуры VDI - vCenter Operations Manager for VMware View (см. предыдущие новости о vCenter Operations тут).
Как мы видим из дэшборда, приведенного на картинке, средство vCenter Operations Manager имеет множество относящихся именно к VMware View метрик и индикаторов (сессии, клиенты, PCoIP). В целом, продукт сфокусирован на отслеживании производительности объектов VDI-инфраструктуры, мониторинге их жизнедеятельности и определении узких мест и источников проблем.
Интересной особенностью VMware vCenter Operations Manager for View является то, что продукт не имеет каких-то предопределенных пороговых значений или дефолтных настроек, которые позволяют определить, все ли в порядке с вашей инфраструктурой. Он запоминает нормальные показатели в процессе мониторинга, а потом сигнализирует о существенных отклонениях от них. Эти показатели наблюдаются в рамках динамических пороговых значений, которые определяются на основе интеллектуального алгоритма.
Вот, например, мы видим, что количество PCoIP-пакетов для десктопа выше обычного:
vCenter Operations Manager для VMware View пропагандирует концепцию "мониторьте все, исправляйте только то, где есть проблемы". Определить, что сломалось поможет цветовое кодирование объектов при "проваливании" в них по иерархии (красный обозначает проблему):
Все это показывается в виде условных очков (видим, что сторадж барахлит):
Далее, идя вниз по иерархии, доходим до производительности конкретных устройств, где vCenter Operations Manager for View показывает признаки проблем (увеличилась latency для чтения и записи):
Ну а на следующем графике мы видим, что все это из-за резкого увеличения числа виртуальных машин:
То есть, vCenter Operations Manager for View позволяет выявлять проблемы на различных уровнях инфраструктуры VDI и выяснять, что именно явилось их причиной. Делается это средствами встроенной базы знаний, в которой заложены зависимости между различными отслеживаемыми метриками в виртуальной среде VMware View.
Также интересно видео, где пользователь звонит в техподдержку и говорит: "мой комп тормозит, в чем дело?". Далее администратор vCenter Operations ищет пользователя в консоли и выясняет, что стряслось с компонентами его десктопа:
Остальные видео тут, а страница продукта vCenter Operations Manager for View находится здесь.
22 мая компания VMware объявила о достижении соглашения по приобретению компании Wanova Mirage, которая занимается поставкой решений для управления образами пользовательских сред в корпоративной ИТ-инфраструктуре.
Если посмотреть на демо-видео от Wanova, то можно понять, что это решение, которое позволяет создать образ рабочей станции пользователя, разделив его на слои (система, приложения, а также данные и настройки пользователя), а потом централизованно управлять такими образами с двух сторон: обновления, резервное копирование, политики и настройки со стороны системного администратора, а также внесение изменений в данные и настройки ПК со стороны пользователя. Работает это все за счет агентов установленных на конечные устройства, обслуживающих кэширование данных и и их двунаправленную синхронизацию, а также управление слоями в целях обновлений, восстановления из бэкапов и т.п.
То есть, это решение для централизации управления и доставки образов ПК на традиционные компьютеры и ноутбуки. Отметим, что VMware приобрела решение Wanova не только с прицелом на виртуальную, но и на физическую среду. Напомним также, что у VMware есть и свое решение для выделения пользовательского слоя в виртуальную сущность - View Persona Management.
С точки зрения виртуальной среды, этот слоистый образ будет называться Centralized Virtual Desktop (CVD). Уже есть мысли по поводу того, как использовать такую концепцию для VMware View и локальных копий виртуальных ПК, которые на стороне клиентов исполняются в VMware Fusion:
То есть такой "сборный десктоп" можно доставлять в физические и виртуальные машины, работающие на различных платформах, в частности, VMware View Local Mode. При этом VMware View и Wanova могут работать как независимо, так и совместно. Например, в случае совместного использования, View отвечает за исполнение ПК на хост-серверах и их доставку на тонкие клиенты, планшеты и нетбуки, а Wanova за управление и доставку образов в физические и виртуальных ПК и ноутбуки, а также передачу образов в виртуальные машины VMware View при взаимодействии с View Composer. Эта концепция будет удобна также и для тех ПК, которые используются разъездными или филиальными работниками без подключения к интернету (на физической или виртуальной платформе).
В конечном итоге, приобретение наработок Wanova даст компании VMware следующие преимущества в сфере end user compiting:
Возможность централизованного управления образами физических и виртуальных ПК из одного решения (конфигурация, обновления, безопасность и т.п.).
Реализация сложных сценариев миграции, например, с Windows XP на Windows 7, где необходимо обновить ОС, оставить приложения, настройки и данные пользователей, а часть десктопов перенести в виртуальную среду на VMware View.
Централизованное резервное копирование и быстрое восстановление данных виртуальных и физических ПК. Отсутствие необходимости больших объемов для хранения бэкапов (хранятся только оригинальные данные).
На словах все это выглядит красиво, хотя VMware придется серьезно поработать, чтобы сделать администрирование этой штуки простым и без многоконсольности. Но это у них и раньше вроде неплохо получалось.
Вы уже, наверняка, читали про новые возможности VMware View 5.1, а на днях обновился калькулятор VDI Flash Calculator до версии 2.8, предназначенный для расчета вычислительных мощностей и хранилищ, поддерживающий новые функции платформы виртуализации настольных ПК.
Среди новых возможностей калькулятора VDI:
Поддержка VMware View 5.1
Поддержка функции VMware View CBRC для системного диска (Content Based Read Cache) - предполагается уменьшение интенсивности ввода-вывода на чтение на 65%
Поддержка связанных клонов на томах NFS для кластеров vSphere, состоящих из более чем 8-ми хостов
Поддержка платформ с высокой плотностью размещения виртуальных ПК
Поддержка разрешения экрана 2560×1600
Небольшие изменения в интерфейсе
Ну и небольшое обзорное видео работы с калькулятором:
Ни для кого не скрет, что государственные организации очень часто и очень много работают с персональными данными (ПДн). Не секрет также, что многие госы уже внедрили виртуальную инфраструктуру VMware vSphere, где есть виртуальные машины, которые эти данные хранят и обрабатывают, что требует соответствующих мер и технических средств защиты, сертифицированных ФСТЭК. К сожалению, сама платформа VMware vSphere имеет недостаток, который я называю "Lack of ФСТЭК", то есть отсутствие своевременно обновляемых сертификатов ФСТЭК на продукт (сейчас актуален сертификат на vSphere 4.1, и нет информации, когда будет сертифицирована пятерка).
Поэтому, когда есть персональные данные и инфраструктура vSphere, просто необходимо использовать единственный имеющийся сейчас на рынке сертифицированный ФСТЭК продукт vGate R2, который позволяет автоматически настроить среду VMware vSphere в соответствии с требованиями общепринятых и отраслевых (специально для России) стандартов, а также защитить инфраструктуру от НСД.
Ниже приведена выдержка из описания кейса внедрения vGate R2 для ТФОМС Приморского края, где была необходима сертифицированная защита среды VMware vSphere:
Перед IT–специалистами и сотрудниками отдела информационной безопасности Фонда была поставлена задача обеспечить в 2011 году защиту информационных массивов персональных данных застрахованных граждан, эксплуатируемых в Фонде по классу информационной безопасности К1.
...
Для выполнения задач защиты системы обработки персональных данных были выбраны продукты vGate и Secret Net 6.5 разработки компании «Код Безопасности».
Реализация проекта по развертыванию ПО vGate осуществлялась на вновь создаваемом ресурсе в виде изолированной аппаратной платформы и развернутой на этой платформе виртуальной инфраструктуры на базе технологии VMware.
Связь с защищенным сегментом осуществляется через аппаратный терминальный клиент, обеспечивающий двухфакторный контроль доступа в защищенную среду центра обработки персональных данных.
Начальник отдела автоматизированной обработки информации ГУ ТФОМС ПК Воробьев П.Б.отметил, что в результате развертывания программного решения vGate для защиты виртуальной инфраструктуры центра обработки персональных данных были решены следующие задачи:
обеспечена защита персональных данных, хранящихся и обрабатываемых в виртуальной среде (ЗСОПДн) от утечек через каналы, специфичные для виртуальной инфраструктуры (контроль виртуальных устройств, обеспечение целостности и доверенной загрузки виртуальных машин и контроль доступа к элементам виртуальной инфраструктуры);
реализовано разделение объектов виртуальной инфраструктуры на логические группы и сферы администрирования с помощью функций мандатного и ролевого управления доступом;
установлен контроль над изменениями настроек безопасности на основе утвержденных корпоративных политик безопасности;
сконфигурирован и запущен в работу АРМ администратора системы безопасности;
реализована регистрация попыток доступа в инфраструктуру, также возможность создания отчетов о состоянии виртуальной инфраструктуры и контроля целостности периметра;
работа с персональными данными в ГУ ТФОМС ПК приведена в соответствие с требованиями законодательства РФ в области защиты информации.
Интересный продукт обнаружился среди корпоративных VDI-решений. Оказывается Citrix XenClient - не единственный клиентский гипервизор, который реализует Type-1 гипервизор, в котором могут быть одновременно запущено несколько виртуальных машин на одном ПК. Есть еще и продукт NxTop от компании Virtual Computer:
По-сути, NxTop - это "тонкий" гипервизор на базе открытого продукта Xen, который позволяет установить компонент NxTop Engine на компьютер без ОС и запускать с его помощью клиентские виртуальные машины на базе Windows и Linux. Преимущества такого подхода те же, что и у XenClient - централизованное развертывание образов ПК, их обновление, возможность иметь рабочий и домашний компьютеры одновременно запущенными на своем ноутбуке, которые изолированы друг от друга, а рабочий - защищен политиками. Несомненный плюс такого подхода - возможность работать Offline, без интернета, в отличие от традиционного VDI-решения.
Помимо самого гипервизора NxTop Engine, есть также компонент NxTop Center, который отвечает за централизованное управление этими гипервизорами и образами ОС. Поставляется он также в виде виртуального модуля (Virtual Appliance), который можно развернуть на платформе Microsoft Hyper-V. А можно просто поставить его в Parent partition на сервере Hyper-V.
Таким образом, в данном решении виртуальные машины запускаются на конечных устройствах (ноутбуки и ПК), а на NxTop Center находятся все службы централизованного обслуживания и управления. То есть, конечные устройства выступают своего рода "хост-серверами", которыми управляет NxTop Center, но на которых запущены не серверы, а клиентские ОС. Из этой консоли и происходит руление ноутбуками и компьютерами, на которых есть виртуальные машины и которые можно обновлять, изменять, накатывать политики и прочее.
Средство управления NxTop Center развертывается на хосте Windows Server 2008 с ролью Hyper-V, где происходит создание виртуальных машин и управление ими, после чего они доставляются на конечные устройства пользователей. При этом на гипервизоре NxTop они запускаются без каких-либо дополнительных модификаций. Можно также создавать виртуальные машины в самом NxTop Engine. Обратите внимание, что и сама консоль NxTop Center похожа на одну из стандартных консолей System Center.
Список совместимости гипервизора NxTop с различными устройствами находится тут: http://www.virtualcomputer.com/hcl. В общем-то, он не маленький.
Сам гипервизор NxTop Engine обладает следующими возможностями:
Поддержка графической подсистемы хоста и вывод на несколько мониторов.
Поддержка сетевых интерфейсов Ethernet, 802.11 wireless LAN, а также модулей 3G/4G.
Функции по переключению между машинами с расширенными возможностями по управлению их питанием (вкл-выкл-suspend).
Поддержка широкого спектра USB-периферии.
Обработка событий оборудования, таких как закрытие крышки ноутбука.
Кстати, все виртуальные машины на клиентских устройствах хранятся в зашифрованном виде.
Средство управления NxTop Center выполняет следующие функции:
Созданиие и модификация виртуальных машин.
Управление пользователями, ролями и разрешениями. Назначение машин пользователям.
Доставка образов на конечные устройства.
Обновление виртуальных машин и их резервное копирование.
Когда NxTop Engine на пользовательском устройстве соединяется с NxTop Center и обнаруживает, что образ виртуальной машины обновился, он посылает обновление пользователю, которое применяется при следующей загрузке компьютера. Также поддерживаются снапшоты состояний ВМ, которые могут служить резервными копиями конфигураций.
Ну и напоследок, небольшая демка о том, как работает NxTop на стороне клиентского устройства:
У NxTop есть бесплатное издание NxTop Express, которое бесплатно для 5-и пользователей, что позволяет сразу приступить к тестированию решения. Потом можно уже купить издание Enterprise.
В общем, штука интересная. А кто-нибудь ее из вас уже пробовал? Как впечатления?
Как и ожидалось, компания VMware в самом начале мая объявила о выпуске новой версии решения для виртуализации настольных ПК VMware View 5.1, в которой появилось несколько значимых нововведений и улучшений. Мы уже писали о новой версии View 5.1 (и тут), где был приведен основной список новых возможностей, а в этой статье разберем их подробнее. Основные нововведения VMware View 5.1 перечислены на картинке ниже...
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
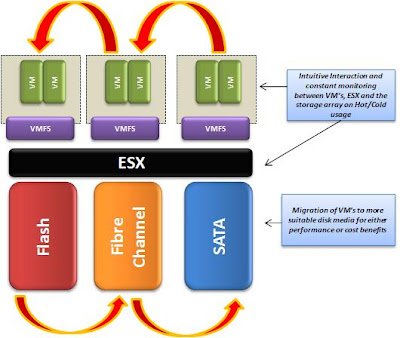
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.
Компания Veeam Software, известная своим продуктом для резервного копирования Veeam Backup and Replication, выпустила финальную версию решения Veeam ONE v6, предназначенного для мониторинга (бывший продукт Veeam Monitor), а также контроля изменений и автоматизированной отчетности (бывший продукт Veeam Reporter) виртуальных инфраструктур VMware vSphere и Microsoft Hyper-V. О новом комплекте поставки решения Veeam ONE мы уже писали тут и тут.
Функции мониторинга:
Функции отчетности:
Теперь два продукта Veeam Reporter и Monitor работают на одном движке с общей базой данных, что делает Veeam ONE законченным решением для управления виртуальной инфраструктурой с точки зрения мониторинга, отчетности, контроля изменений и планирования мощностей. Все в одном.
Новые возможности Veeam ONE v6:
Мониторинг
New monitoring views - новые представления дэшбордов summary, alarm и resource, позволяющие осуществлять быструю навигацию вглубь объектов.
Read-only access to monitoring clients - для клиентов, которым нужны только функции наблюдения за виртуальной средой, можно ограничить права на изменения объектов.
Logical groupings of performance counters - пользователь несколькими кликами может поместить на графики метрики различных категорий для отслеживания возможных зависимостей между ними.
Детализация
Detailed views - для многих объектов можно "проваливаться" вниз с максимальным уровнем детализации.
Child object status display - индикаторы статуса родительских объектов дают представление о том, что происходит с дочерними, и какие у них могут быть проблемы.
Generating reports from widgets - с помощью виджетов в Veeam ONE можно быстро сгенерировать отчет, отражающий заданный период времени.
Тревоги (Alarms)
New alarms - теперь еще большее количество алармов.
Default action - при срабатывании аларма автоматически посылается нотификация по почте всем, кто находится в группе default notification group.
Filtering - фильтры по тревогам могут быть основаны на базе error level, status, object type и времени.
Exclusions - исключения для алармов, которые можно применить к различным объектам: виртуальным дискам, сенсорам оборудования на хостах и т.п.
Email customization - редактирование поля subject и формата нотификаций.
Configurable email notification groups - можно задавать, кто получает нотификации по группам событий.
Отчетность
Overview reports - отчеты по Storage capacity, storage usage, а также обзорные отчеты infrastructure, hypervisor,
clusters и VMs.
Monitoring reports - отчеты по мониторингу: Alarms, uptime ВМ, производительность кластера, хостов и виртуальных машин, включая отчет по потребителям наибольшего количества ресурсов.
(VMware only) Optimization reports - ВМ с перевыделенными или недовыделенными ресурсами, снапшотами, лишними файлами, а также простаивающие ВМ и шаблоны, выключенные ВМ.
(VMware only) Change tracking reports - отслеживание изменений в настройках пользователем или объектом, а также изменения пермиссий.
Integration - дэшборды можно встраивать в письма оповещений, веб-порталы и сторонние приложения.
Access control - для доступа к дэшбордам могут быть заданы разрешения для пользователей.
Автоматическое обновление и бизнес-категоризация
Automatic updates - по запросу Veeam ONE v6 проверяет и загружает обновления репорт-паков, дэшбордов и виджетов.
Business views - представления мониторинга и отчетности могут быть настроены в соответствии с категоризацией, заданной пользователем. Т.е. эти представления можно сделать на основе бизнес или географических критериев.
Standalone hosts - отдельно стоящие хост-серверы также включаются в категоризацию.
Sample categorization - схема бизнес-категоризации, которая показывает пример, как это делать.
Сбор данных в виртуальной среде
Automatically triggered data collection - после установки Veeam ONE сразу же начинается периодический сбор данных с хост-серверов.
Controlled query load - данные о производительности и конфигурации собираются в различных задачах, что позволяет более гибко подходить к распределению нагрузки этими задачами на хост-серверы.
Granular performance history - в Veeam ONE v6 сохраняется гранулярная история производительности за длительный промежуток времени, включающая в себя данные мониторинга и отчетности.
Поддержка VMware vSphere 5
Datastore maximum queue depth - Veeam ONE v6 включает эту новую метрику vSphere 5.
Storage clusters - мониторинг и оповещения по кластерам хранилищ vSphere 5.
Поддержка Microsoft Hyper-V
Alarms - Veeam ONE имеет 90 алармов для хостов и других объектов Hyper-V.
Full monitoring support for Failover Clusters - для кластеров Hyper-V поддерживаются все функции мониторинга, включая алармы, отчеты, чарты и статьи базы знаний для томов CSV.
Direct collection of performance data - данные о производительности собираются напрямую с хост-серверов, включая хосты без SC VMM, что позволяет контролировать больше, чем сам SC VMM.
Решение Veeam ONE v6 для Microsoft Hyper-V и VMware vSphere можно скачать по одной ссылке тут.
Компания VMware еще 14 апреля запустила портал самообслуживания пользователей, где они могут управлять своими лицензионными ключами (регистрировать, даунгрейдить) и работать с технической поддержкой по продуктам VMware, который называется My VMware.
Как видно из картинки, вход на портал доступен с основной страницы сайта VMware. Также на него можно зайти по адресу:
Зарегистрировавшись на этом портале, пользователь получает доступ к интерфейсу управления лицензионными ключами продуктов, контрактами технической поддержки и пользователями организации. Пользователи организации разделяются на различные категории, для которых определяются роли, которым позволено смотреть лицензионные ключи, проводить с ними операции (даунгрейд, комбинирование, разделение и т.п.). Оттуда же можно сформировать запрос на продление поддержки (SnS) и написать в поддержку.
В общем, для тех, кто является пользователем продуктов Citrix, скажем, что это, по-сути, то же самое, что и MyCitrix, может даже несколько больше.
Партнеры VMware, которые регистрируются как отдельная категория пользователей, получают еще и доступ к различным партнерским инструментам для продаж, маркетинга и прочее. Штука эта очень насыщенная всяким функционалом, поэтому если вы покупали VMware vSphere и прочие продукты или продаете их - советую зарегистрироваться там.
В последнее время вышло просто море статей KB по использованию My VMware, приведем наиболее полезные из них:
Вот видео с обзором навигации по My VMware. Как всегда сделано так, чтобы ничего не было видно, но основные секции понятны:
А вот так, например, можно самостоятельно даунгрейдить лицензии:
Эта штука всем хороша, кроме одного - она не работает. Например, мои креды не подхватились, при сбросе пароля (2 раза) - залогиниться я никуда не смог. Много лет назад мы также сдавали проект госкомиссии - открыли страницу сайта, а залогиниться не смогли. Рассказывали образами. Вот так и VMware показывает мне только видео.
И, напоследок, гвоздь программы. My VMware - смешная кнопка:
Для решения этой проблемы нам предлагают почистить кэш браузера (фантастика - есть статья KB как справиться с кнопкой). Но даже если вы с ней справитесь, то хрен залогинитесь.
Таги: VMware, My VMware, vSphere, Enterprise, Licensing
На блоге vMind.ru уже писали о просочившихся в интернет подробностях о новых возможностях решения для виртуализации настольных ПК VMware View 5.1, а мы сегодня осветим еще несколько интересных моментов.
Большинство нововведений VMware View 5.1 показаны на этом слайде:
Основная новая функция - это, конечно же, VMware View Storage Accelerator, которая позволяет использовать оперативную память сервера для кэширования наиболее часто используемых блоков данных виртуальных ПК, запрашиваемых с конечного устройства. Делается это средствами технологии Content Based Read Cache (CBRC), поддержка которой уже имеется в VMware vSphere 5.0. Эта штука, само собой, положительно влияет на скорость обмена данными с конечными устройствами и производительность операций ввода-вывода для виртуальных ПК, поскольку блоки запрашиваются напрямую из памяти:
Этот тест проводился для 50 виртуальных ПК с гостевой ОС Windows 7 и были достигнуты следующие результаты:
Увеличение до 80% пиковых IOPS
Увеличение на 45% средних IOPS
Увеличение пиковой скорости обмена с ПК до 65%
Увеличение средней скорости обмена с ПК на 25%
Настройки кэширования на хосте ESXi задаются в конфигурации VMware View Manager 5.1:
При этом, как и всегда, данная техника оптимизации полностью прозрачна для виртуальных машин, средств управления и прочего.
Полный список нововведений VMware View 5.1:
Расширенные техники по оптимизации хранилищ и интеграции с устройствами хранения:
View Storage Accelerator: использование локального кэша Content Based Read Cache (CBRC) на хосте vSphere 5.0
View Composer API Integration (находится в стадии Tech Preview): теперь операции по клонированию десктопов в View Composer используют технологию vStorage API for Array Integration (VAAI) Native Cloning для дисковых массивов NAS. Это позволит ускорить развертывание виртуальных ПК.
В View Composer можно будет задавать букву диска в гостевой ОС для disposable disk (своп и временные файлы)
Поддержка до 32-х (вместо 8) хостов в кластере, когда используется NAS-хранилище
Улучшенная поддержка USB-устройств, т.е. подключаемые к оконечному ПК устройства новых моделей (планшеты, камеры и т.п.) будут видны в виртуальном ПК
Поддержка двухфакторной аутентификации Radius
Улучшения административного интерфейса View Manager
Поддержка аккаунтов ПК в Active Directory, которые были созданы перед внедрением View
Программа VMware по улучшению качества работы в виртуальных ПК
Поддержка виртуальных профилей (Virtual Profiles) для физических ПК
Использование возможностей виртуальных профилей как средства миграции десктопа в виртуальную машину
Поддержка установки сервера View Composer на отличный от vCenter сервер
Теперь, что касается даты выхода VMware View 5.1. Анонсировано решение будет 2-3 мая (согласно информации CRN), а доступно для загрузки будет уже 9 мая. При этом VMware View 5.1 будет включать в себя vCenter Operations for View, который будет доступен как аддон за дополнительные деньги.
В начале апреля компания Microsoft объявила о выпуске решений Microsoft User Experience Virtualization (UE-V) и Microsoft Application Virtualization (App-V) 5.0 (сейчас в бете), входящих в состав пакета Microsoft Desktop Optimization Pack (MDOP). Безусловно, заслуживает внимания новый продукт User Experience Virtualization, который представляет собой средство виртуализации пользовательского окружения и позволяет сохранять настройки приложений и рабочей среды, вне зависимости от того, с какого устройства и по какой модели (физ. или виртуальный ПК) происходит доступ пользователя.
Надо отметить, что средство UE-V позволяет управлять только настройками приложений и ОС, но не файлами пользователей. Для данных предлагается использовать технологии Folder Redirection и Offline Files. При этом UE-V может управлять настройками приложений только в папке C:\Users\Username.
Ключевым понятием UE-V является шаблон настроек для приложения (template), который представляет собой XML-файл с информацией о том, где хранятся настройки приложения или ОС (реестр и файловая система). Местом хранения является обычная сетевая шара, доступная в сети для пользователя.
При этом UE-V идет сразу со следующими готовыми шаблонами приложений:
Internet Explorer 9 and 10 (favorites, home page, tabs и toolbars)
Windows applications (Calculator, Notepad, Wordpad)
С точки зрения настроек Windows в UE-V есть такие шаблоны:
Themes (тема рабочего стола с картинкой, цветность, звуки, скринсейвер)
Ease of access (настройки accessibility и ввода с клавиатуры)
Если пользователь вносит "неправильные" с точки зрения администратора настройки приложений, последний может откатить их назад принудительно. UE-V поддерживает ОС Windows 7, Windows 8 (client и server), а также Windows Server 2008 R2. Что интересно UE-V может работать совместно с App-V, синхронизируя настройки, например, между физически установленным Outlook и его виртуализованной копией на той же машине.
Также приведем некоторые новые возможности Microsoft Application Virtualization (App-V) 5.0 Beta:
Возможность коммуникации между локальной копией приложения и его виртуализованной копией на одной машине
Не треубется указания буквы диска для пакета, а также убрали ограничение на 4 ГБ для виртуального пакета
Веб-консоль управления, реализующая основные возможности администратора
Расширенная поддержка PowerShell
Скачать продукты можно по этим ссылкам: UE-V и App-V 5.0.
Мы недавно писали о новых возможностях продукта для создания отказоустойчивых iSCSI-хранилищ StarWind 5.8 (а тут можно почитать про производительность), а завтра вы можете лично убедиться в превосходстве StarWind над конкурентами и над тем, когда его у вас нет. Для этого завтра надо прийти на вебинар, тем более, что докладчик - наш с вами знакомый, Анатолий Вильчинский из Киева:
Как знают администраторы VMware vSphere в крупных компаниях, в этой платформе виртуализации есть фреймворк, называющийся VMware Pluggable Storage Architecture (PSA), который представляет собой модульную архитектуру работы с хранилищами SAN, позволяющую использовать ПО сторонних производителей для работы с дисковыми массивами и путями.
Выглядит это следующим образом:
А так понятнее:
Как видно из второй картинки, VMware PSA - это фреймворк, работа с которым происходит в слое VMkernel, отвечающем за работу с хранилищами. Расшифруем аббревиатуры:
VMware NMP - Native Multipathing Plug-In. Это стандартный модуль обработки ввода-вывода хоста по нескольким путям в SAN.
Third-party MPP - Multipathing plug-in. Это модуль стороннего производителя для работы по нескольким путям, например, EMC Powerpath
VMware SATP - Storage Array Type Plug-In. Это часть NMP от VMware (подмодуль), отвечающая за SCSI-операции с дисковым массивом конкретного производителя или локальным хранилищем.
VMware PSP - Path Selection Plug-In. Этот подмодуль NMP отвечает за выбор физического пути в SAN по запросу ввода-вывода от виртуальной машины.
Third-party SATP и PSP - это подмодули сторонних производителей, которые исполняют означенные выше функции и могут быть встроены в стандартный NMP от VMware.
MASK_PATH - это модуль, который позволяет маскировать LUN для хоста VMware ESX/ESXi. Более подробно о работе с ним и маскировании LUN через правила написано в KB 1009449.
Из этой же картинки мы можем заключить следующее: при выполнении команды ввода-вывода от виртуальной машины, VMkernel перенаправляет этот запрос либо к MPP, либо к NMP, в зависимости от установленного ПО и обращения к конкретной модели массива, а далее он уже проходит через подуровни SATP и PSP.
Уровень SATP
Это подмодули, которые обеспечивают работу с типами дисковых массивов с хоста ESXi. В составе ПО ESXi есть стандартный набор драйверов, которые есть под все типы дисковых массивов, поддерживаемых VMware (т.е. те, что есть в списке совместимости HCL). Кроме того, есть универсальные SATP для работы с дисковыми массивами Active-active и ALUA (где LUN'ом "владеет" один Storage Processor, SP).
Каждый SATP умеет "общаться" с дисковым массивом конкретного типа, чтобы определить состояние пути к SP, активировать или деактивировать путь. После того, как NMP выбрал нужный SATP для хранилища, он передает ему следующие функции:
Мониторинг состояния каждого из физических путей.
Оповещение об изменении состояний путей
Выполнение действий, необходимый для восстановления пути (например failover на резервный путь для active-passive массивов)
Посмотреть список загруженных SATP-подмодулей можно командой:
esxcli nmp satp list
Уровень PSP
Path Selection Plug-In отвечает за выбор физического пути для I/O запросов. Подмодуль SATP указывает PSP, какую политику путей выставить для данного типа массива, в зависимости от режима его работы (a-a или a-p). Вы можете переназначить эту политику через vSphere Client, выбрав пункт "Manage Paths" для устройства:
Для LUN, презентуемых с массивов Active-active, как правило, выбирается политика Fixed (preferred path), для массивов Active-passive используется дефолтная политика Most Recently Used (MRU). Есть также и еще 2 политики, о которых вы можете прочитать в KB 1011340. Например, политика Fixed path with Array Preference (VMW_PSP_FIXED_AP) по умолчанию выбирается для обоих типов массивов, которые поддерживают ALUA (EMC Clariion, HP EVA).
Надо отметить, что сторонний MPP может выбирать путь не только базовыми методами, как это делает VMware PSP, но и на базе статистического интеллектуального анализа загрузки по нескольким путям, что делает, например, ПО EMC Powerpath. На практике это может означать рост производительности доступа по нескольким путям даже в несколько раз.
Работа с фреймворком PSA
Существуют 3 основных команды для работы с фреймворком PSA:
esxcli, vicfg-mpath, vicfg-mpath35
Команды vicfg-mpath и vicfg-mpath35 аналогичны, просто последняя - используется для ESX 3.5. Общий список доступных путей и их статусы с информацией об устройствах можно вывести командой:
vicfg-mpath -l
Через пакет esxcli можно управлять путями и плагинами PSA через 2 основные команды: corestorage и nmp.
Надо отметить, что некоторые команды esxcli работают в интерактивном режиме. С помощью nmp можно вывести список активных правил для различных плагинов PSA (кликабельно):
esxcli corestorage claimrule list
Есть три типа правил: обычный multipathing - MP (слева), FILTER (аппаратное ускорение включено) и VAAI, когда вы работаете с массивом с поддержкой VAAI. Правила идут в порядке возрастания, с номера 0 до 101 они зарезервированы VMware, пользователь может выбирать номера от 102 до 60 000. Подробнее о работе с правилами можно прочитать вот тут.
Правила идут парами, где file обозначает, что правило определено, а runtime - что оно загружено. Да, кстати, для тех, кто не маскировал LUN с версии 3.5. Начиная с версии 4.0, маскировать LUN нужно не через настройки в vCenter на хостах, а через объявление правил для подмодуля MASK_PATH.
Для вывода информации об имеющихся LUN и их опциях в формате PSA можно воспользоваться командой:
esxcli nmp device list
Можно использовать всю ту же vicfg-mpath -l.
Ну а для вывода информации о подмодулях SATP (типы массивов) и PSP (доступные политики путей) можно использовать команды:
esxcli nmp satp list
esxcli nmp psp list
Ну а дальше уже изучайте, как там можно глубже копать. Рекомендуемые документы:
Схема очень проста - StarWind iSCSI можно использовать как для продуктивного хранилища, так и для хранилища резервных копий:
В документе рассматривается вариант использования отказоустойчивого iSCSI-хранилища StarWind в производственной среде, где применяются такие возможности StarWind как:
Снапшоты хранилищ
Дедупликация
Отказоустойчивая конфигурация из двух серверов хранения, обеспечивающая непрерывную работу виртуальных машин в случае отказа одного из них
На сайте проекта VMware Labs, о котором мы не раз писали, появился новый технический журнал для администраторов платформы виртуализации VMware vSphere и других продуктов - VMware Technical Journal. Первый номер насчитывает 80 страниц:
Предполагается, что это издание, освещающее основные активности R&D-подразделения VMware, будет выходить на регулярной основе и представлять все основные новинки и продукты, над которыми работает VMware, с технической стороны. Вот темы первого номера:

 RSS
RSS